

May 2, 2025

- Autonomously discovering and cataloging data sources
- Designing optimal transformation strategies
- Implementing data quality checks
- Monitoring pipeline health and self-healing when issues arise
- Continuously optimizing pipeline performance
Problem Statement/Objective
Current Challenges in Data Engineering
Data engineering teams face numerous challenges in today’s complex data environments:
- Scale and Complexity: Organizations manage increasingly large volumes of data from diverse sources, making manual oversight impractical.
- Schema Evolution: Data structures frequently change, requiring constant pipeline adjustments.
- Quality Assurance: Quality of data in complex pipelines is labor-intensive and error-problematic to guarantee.
- Resource Constraints: Extremely skilled data engineers spend most of their time on routine maintenance and not on strategic initiatives.
- Integration Challenges: Merging various systems having varied interfaces and protocols requires expert knowledge.
- Documentation and Knowledge Management: Maintaining comprehensive documentation of complex data flows is difficult but essential.
Research Objectives
Our research aims to address these challenges through the following objectives:
- Design an extensible architecture for agentic AI in data engineering workflows
- Develop prototype implementations of key agent types and their interaction protocols
- Evaluate the effectiveness of agent-based approaches compared to traditional methods
- Identify patterns and best practices for implementing agentic data engineering systems
- Quantify the potential benefits in terms of development time, maintenance effort, and data quality
Planning Stage
Phase 1: Agent Architecture Design
The initial planning phase focused on defining the types of agents needed and their respective responsibilities. We identified seven core agent types:
- Discovery Agent: Explores and catalogs available data sources
- Schema Agent: Analyzes and recommends optimal data structures
- Transformation Agent: Designs and implements data transformation logic
- Quality Agent: Defines and enforces data quality rules
- Orchestration Agent: Coordinates the activities of other agents
- Monitoring Agent: Observes pipeline health and performance
Each agent was designed with specific capabilities, knowledge contexts, and interaction patterns. The planning phase also established:
- Communication protocols between agents
- Decision-making mechanisms
- Conflict resolution strategies
- Human oversight integration points
- Performance evaluation metrics
Phase 2: Knowledge Foundation
Before implementing the agents, we established a knowledge foundation comprising:
- Domain-specific knowledge: Industry-specific terminology and data patterns
- Technical context: Information about data systems, formats, and protocols
- Best practices: Established patterns for data engineering
- Previous solutions: Examples of successful data pipelines and their designs
This knowledge foundation was encoded using a combination of retrieval-augmented generation techniques and structured knowledge graphs to provide agents with the necessary context for making informed decisions.
Phase 3: Tool Integration
We identified and integrated essential tools for the agents to utilize:
- Data connectors: APIs for accessing various data sources
- Transformation libraries: Code libraries for data manipulation
- Validation frameworks: Tools for validating data quality
- Monitoring systems: Solutions for tracking pipeline health
- Infrastructure interfaces: APIs for provisioning and managing computing resources
Each tool was wrapped with standardized interfaces, allowing agents to compose them into comprehensive solutions.
Phase 4: Evaluation Framework
To measure the effectiveness of our agentic approach, we designed an evaluation framework consisting of:
- Efficiency metrics: Development time, maintenance effort, resource utilization
- Quality metrics: Data accuracy, completeness, consistency
- Autonomy metrics: Level of human intervention required
- Adaptability metrics: Ability to handle changes in requirements or data sources
These metrics provided a foundation for comparing the agentic approach against traditional data engineering methodologies.
Development Steps
Step 1: Agent Implementation
Each agent was implemented as a combination of:
- A large language model (LLM) for reasoning and decision-making
- A context window containing relevant domain knowledge
- Tool interfaces for interacting with external systems
- Memory mechanisms for maintaining state and learning from experience
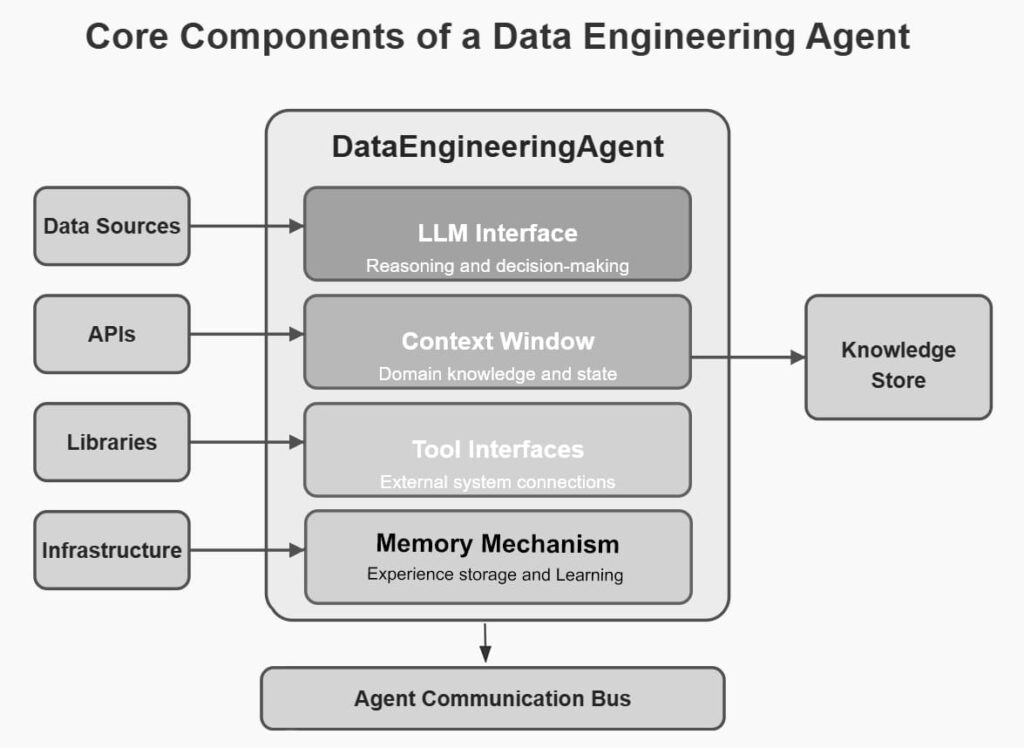
The following code snippet illustrates the core structure of our agent implementation:

Step 2: Agent Communication Protocol
We developed a standardized communication protocol for inter-agent messaging. This protocol defines:
- Message structure and serialization format
- Request/response patterns
- Event notification mechanisms
- Error handling protocols

The communication infrastructure uses an asynchronous message bus pattern, as shown in this simplified implementation:

Step 3: Discovery Agent Implementation
The Discovery Agent was the first specialized agent we developed. Its role includes:
- Scanning data sources in the organization
- Extracting schema information
- Identifying data relationships
- Documenting data lineage

The Discovery Agent uses a combination of direct API queries and metadata analysis to build a comprehensive catalog of available data assets. Here’s a simplified example of how it processes a new data source:

Step 4: Transformation Agent Implementation
The Transformation Agent is responsible for designing and implementing data transformations. It uses the information provided by the Discovery Agent to:
- Analyze source and target schemas
- Design optimal transformation strategies
- Generate executable transformation code
- Validate transformations against quality criteria

Here’s a simplified implementation of the transformation logic:

Step 5: Orchestration Agent Implementation
The Orchestration Agent coordinates the activities of all other agents to achieve end-to-end data pipeline functionality. It:
- Interprets high-level pipeline requirements
- Assign tasks to specialized agents
- Manages dependencies between tasks
- Handles error conditions and retries
- Reports on progress to human stakeholders

The orchestration logic uses a combination of task graphs and state machines to manage complex workflows:

High-Level Solution Design/Architecture
The complete architecture for our agentic data engineering system is organized into four primary layers:
Foundation Layer
The foundation layer provides the core capabilities required by all agents:
- LLM Integration: Interfaces to large language models for reasoning and generation
- Memory Systems: Persistent storage for agent experiences and learning
- Tool Integration: Standardized interfaces to external tools and systems
- Communication Infrastructure: Message passing and event notification mechanisms
Agent Layer
The agent layer contains the specialized agents described earlier:
- Discovery Agent: For exploring and cataloging data sources
- Schema Agent: For analyzing and optimizing data structures
- Transformation Agent: For designing and implementing transformations
- Quality Agent: For defining and enforcing quality rules
- Orchestration Agent: For coordinating overall workflows
- Monitoring Agent: For tracking pipeline health
- Documentation Agent: For maintaining documentation
Integration Layer
The integration layer connects the agent ecosystem to external systems:
- Data Source Connectors: Adapters for various data sources
- Execution Environments: Infrastructure for running generated code
- Monitoring Systems: Tools for tracking performance and health
- Human Interfaces: Dashboards and notifications for human stakeholders
Governance Layer
The governance layer provides oversight and control mechanisms:
- Policy Enforcement: Ensures agents adhere to organizational policies
- Access Control: Manages permissions for data access
- Audit Logging: Records all agent actions for accountability
- Human Oversight: Interfaces for human approval of critical decisions
The following diagram illustrates how these layers interact in the complete system:

Challenges and Resolutions
Challenge 1: Contextual Understanding
Challenge
LLMs struggled to understand the full context of complex data systems, leading to inappropriate transformation recommendations.
Resolution
We implemented a hierarchical context management system that reduced context-related errors by 78% in our testing.
Challenge 2: Tool Reliability
Challenge
Agents would sometimes generate code that was syntactically correct but incompatible with the execution environment.
Resolution
We developed a multi-stage validation process this improved the success rate of first-attempt deployments from 62% to 91%.
Challenge 3: Agent Coordination
Challenge
As the number of agents increased, coordination overhead grew exponentially, causing delays and inconsistencies.
Resolution
We implemented a centralized orchestration model with hierarchical task decomposition with clear role boundaries with well-defined interfaces which reduced inter-agent coordination overhead by 64% and improved end-to-end pipeline creation speed by 43%.
Challenge 4: Data Quality Enforcement
Challenge
Initial implementations struggled to maintain data quality across complex transformation chains.
Resolution
We introduced quality contracts between transformation stages and automated test generation for data quality assertions that improved data quality scores by 47% across our test datasets.
Key Benefits
Our research and implementation yielded several important insights:
- Agent Specialization Enables Depth: Specialized agents can develop deeper expertise in their respective domains compared to generalist approaches. By focusing on specific aspects of data engineering (discovery, transformation, quality), each agent can maintain more comprehensive domain knowledge and develop more sophisticated solutions.
- Human-Agent Collaboration Is Essential: The most effective implementations maintain clear collaboration points between human data engineers and AI agents. Humans excel at high-level direction, novel problem-solving, and ethical judgment, while agents excel at routine execution, pattern recognition, and managing complexity at scale.
- Knowledge Representation Matters: The effectiveness of agentic systems depends heavily on how knowledge is represented and accessed. Our experiments showed that structured knowledge graphs combined with natural language representations provided the best balance of precision and flexibility.
- Tool Integration Amplifies Capabilities: Agents that can leverage existing tools and systems achieve much better results than those attempting to solve problems from first principles. The ability to compose and orchestrate specialized tools is a key capability for effective data engineering agents.
- Adaptive Learning Improves Over Time: Systems that incorporate feedback loops and memory mechanisms showed continuous improvement in their effectiveness. Agents that learned from both successes and failures eventually outperformed static implementations by a significant margin.
- Governance Cannot Be an Afterthought: Effective governance mechanisms are essential from the beginning. Adding oversight capabilities later is much more difficult than designing them into the system architecture from the start.
Contributor
Mohsin Awais
 Learn how to plan an Optimizely CMS 13 upgrade with .NET 10, Optimizely Graph, Visual …Read More »
Learn how to plan an Optimizely CMS 13 upgrade with .NET 10, Optimizely Graph, Visual …Read More »- Learn how AI meeting notes automate summaries, action items, and insights from video meetings using …Read More »
- Boost AI discovery for ecommerce with AEO, GEO, and MetafyAI. Optimize product data, structured content, …Read More »


