
Home > Blogs > Optimizely > From Traditional A/B Testing to AI-Driven Experimentation. The Modern Journey of Optimizely Web Experimentation
May 26, 2026
From Traditional A/B Testing to AI-Driven Experimentation. The Modern Journey of Optimizely Web Experimentation
Table of Contents
Websites used to be something you built once and basically forgot about. That doesn’t work anymore. The companies actually winning online treat their site as a living product — something they’re constantly tweaking, testing, and rebuilding in small ways based on what real users do.
Web experimentation has changed a lot in the last few years. What started as plain A/B testing is now a real growth lever, powered by data and increasingly by AI. Optimizely is one of the platforms making that possible — letting teams ship test ideas, watch how users actually behave, and refine experiences in something close to real time. The wins aren’t always huge on their own. But they stack. Conversion rates, engagement, revenue — all of it compounds the longer you keep at it.
That’s where we come in. Royal Cyber is a certified Optimizely partner that helps enterprises stand up, scale, and modernize their AI-driven experimentation platform — whether you’re running your first A/B testing confirguration or building an optimization engine that touches every page on your site.
Ready to make experimentation a real growth lever, not a side project?
Where It All Started: The Early Days of Testing
Early on, most digital decisions came down to gut feel. Someone in a meeting liked option B better, a designer pushed for a particular layout, leadership had an opinion. Things shipped fast, sure. But the user experience was inconsistent, and a lot of money walked out the door because of small choices nobody ever questioned.
A/B testing changed that. Suddenly you didn’t have to argue about which headline was better — you could just put both in front of real users and see which one actually got more clicks. That sounds obvious now. At the time it was a small revolution, and it kicked off what people started calling a data-driven culture. Decisions stopped being about who in the room had the loudest opinion.
But there was a ceiling. Tests were slow. Setting them up took engineering effort. And you could only really run a handful of them at any given moment.
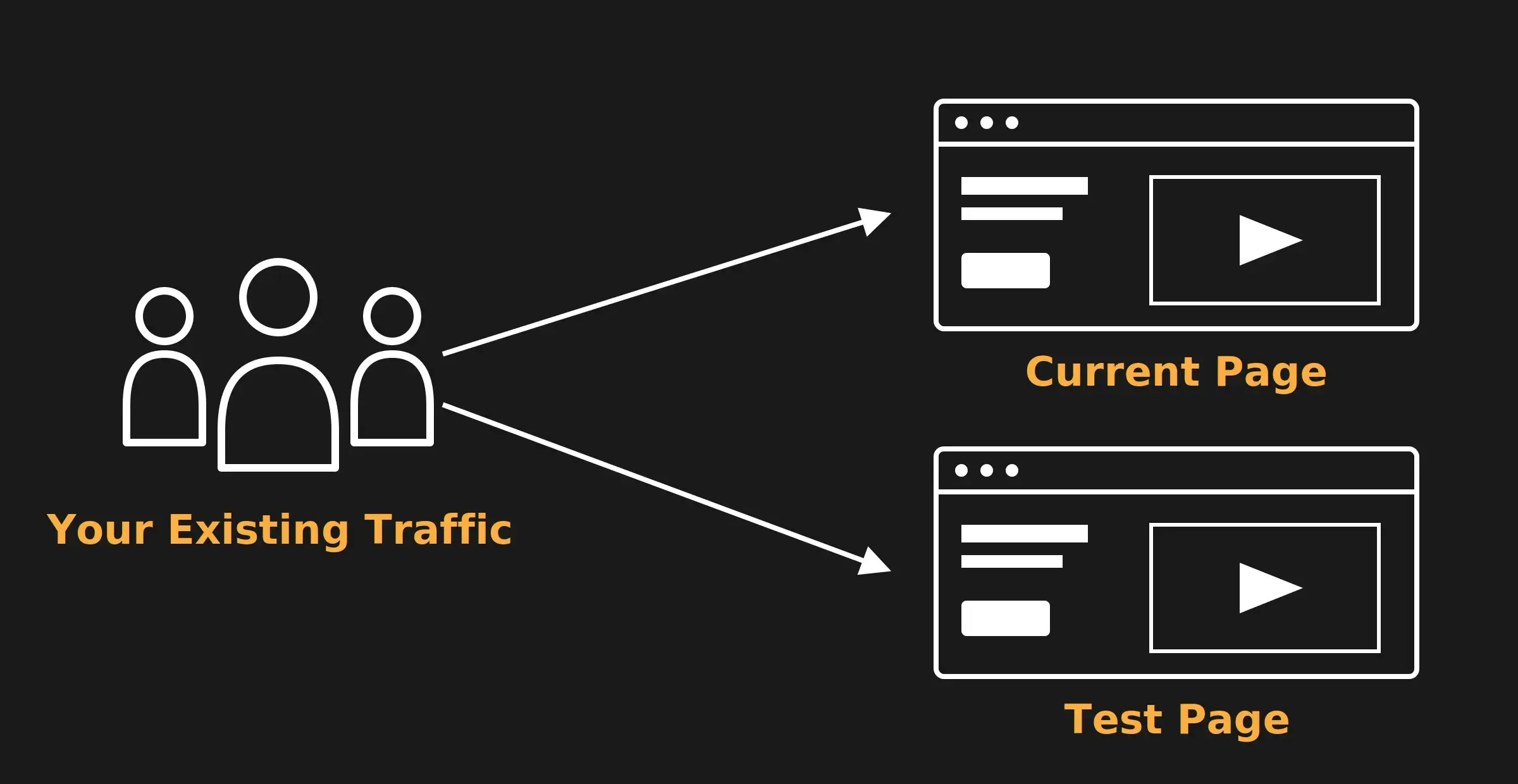

How a Typical Experiment Works
The basic loop hasn’t really changed. You start with a hypothesis — a guess about what might move the needle. Maybe a different headline. A new CTA color. A pricing page rearrangement. You build the variation, split your traffic between control and the new version, and wait for the numbers to tell you which one wins.
Conversion Rate = Conversions ÷ Total Visitors
That formula is the easy part. The hard part is doing the test right. You need enough traffic for the numbers to mean something, the traffic split has to be clean (no weird seasonality skewing one side), and you have to be honest about statistical significance instead of calling a winner the second something looks promising. Skip any of that and your “winning” variation is basically a coin flip.
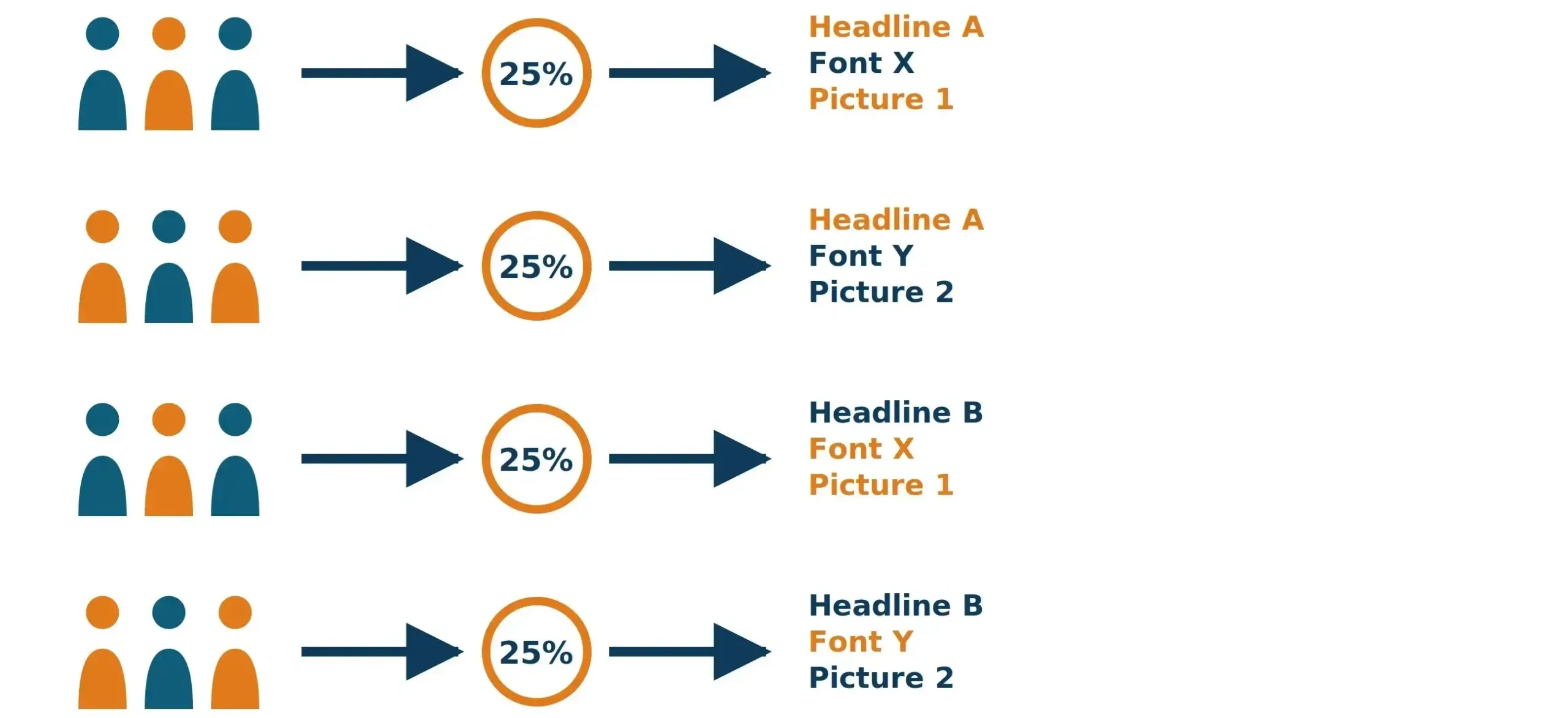
The Limitations of Traditional A/B Testing
A/B testing solved a real problem. But as companies scaled it up they ran into new ones.
- Tests took forever to reach significance. Weeks. Sometimes months.
- Prioritizing what to test became its own headache — every PM had ten ideas and there wasn’t a good way to rank them.
- Low-traffic pages were almost impossible to test. Not enough visitors meant nothing ever moved out of the noise.
- And once a test was running, traffic stayed locked at 50/50 even when the variation was obviously crushing the control.
The thing that was supposed to make teams faster ended up slowing them down. Especially for companies trying to keep pace in markets where competitors were shipping changes every week.
Which is what makes the A/B testing vs AI experimentation conversation so relevant right now. The old approach solved one problem and created a new one — it just couldn’t keep up once experimentation needed to happen at scale.
The Shift Toward AI-Driven Experimentation
The fix was to bring AI and automation into the loop. That turned experimentation from a thing you set up, ran, and reviewed into something closer to a continuous system — always on, always learning.
Modern Optimizely sits in this category: less of a plain testing tool, more of an AI-driven experimentation platform doing the heavy lifting in the background.
A few things changed:
- AI now suggests what to test based on actual user behavior patterns, not just what someone wrote on a sticky note.
- Multi-armed bandit algorithms shift traffic dynamically toward whichever variation is winning, so you stop losing money on the losing side mid-test.
- Performance data comes through in real time. No more waiting two weeks to find out something was broken on day three.
- Different segments can see different experiences without anyone manually building five variants.
Instead of running a test, calling it, and moving on, the system keeps adapting while the test is still going. You learn and optimize at the same time.
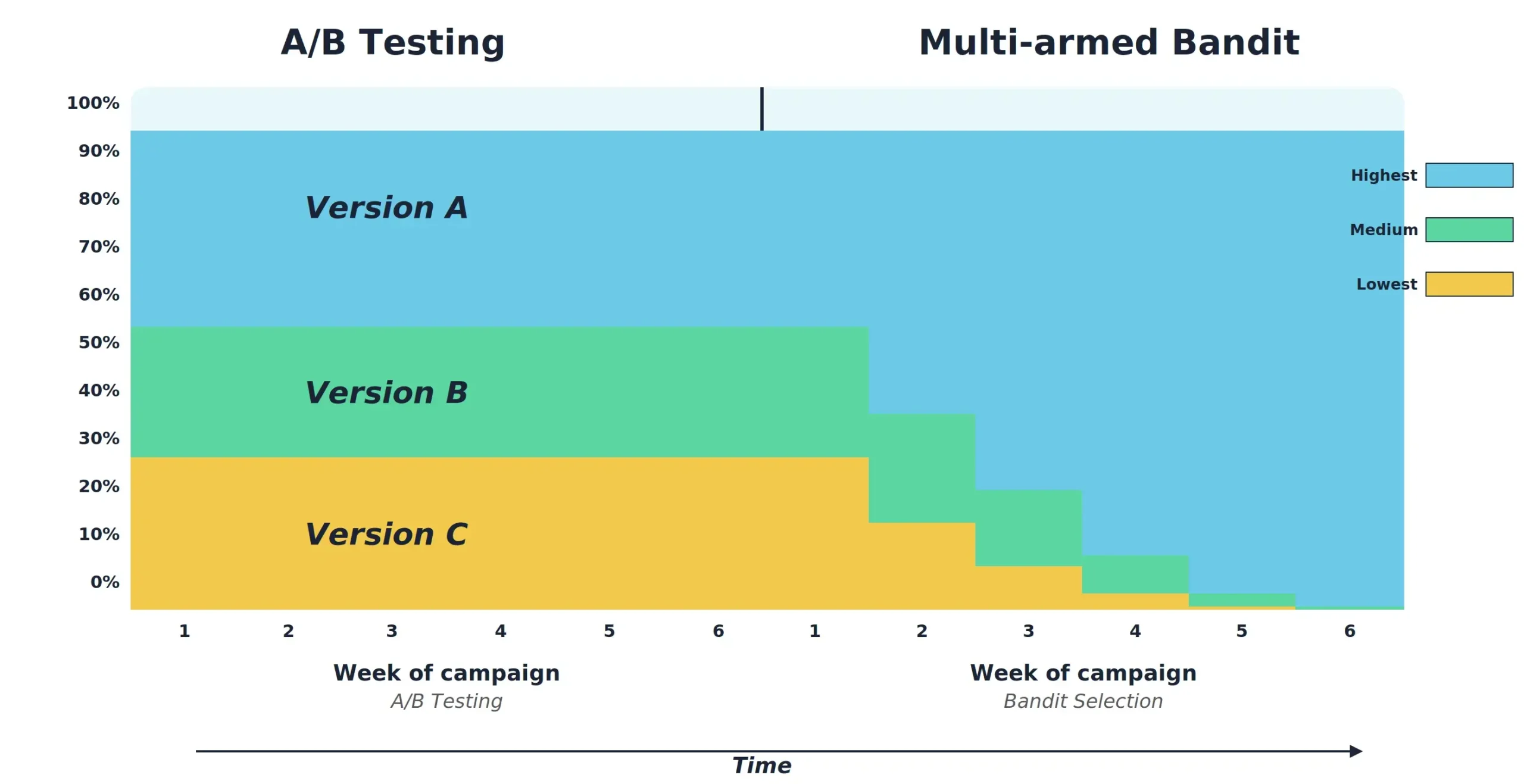
Not sure where your experimentation program sits on the maturity curve?
The Experimentation Maturity Journey
Most organizations don’t go from zero to AI-driven overnight. They move through stages, and where you sit on this ladder usually says more about your team’s discipline than the tools they use:
- A test here and there, mostly when someone has a strong opinion. Limited impact.
- There’s a testing roadmap now, and a regular cadence. Things are starting to feel intentional.
- Multiple teams are running their own experiments. It’s part of how people work, not a special project.
- AI-driven, continuously optimizing. Experimentation isn’t a separate function — it’s just how the site evolves.
The jump between any two of these stages is bigger than people think. It’s not just about buying a better tool. It’s about how deep experimentation actually goes into the way decisions get made.
Measuring the Impact of Experimentation
You don’t really see the value of experimentation in any single test. You see it over time.
A single experiment might bump a conversion rate by 2%. Not exciting. But run thirty of those in a year and the picture changes. Companies that stick with it build a growth curve that just keeps going up while their competitors are stuck doing seasonal redesigns and hoping for the best.
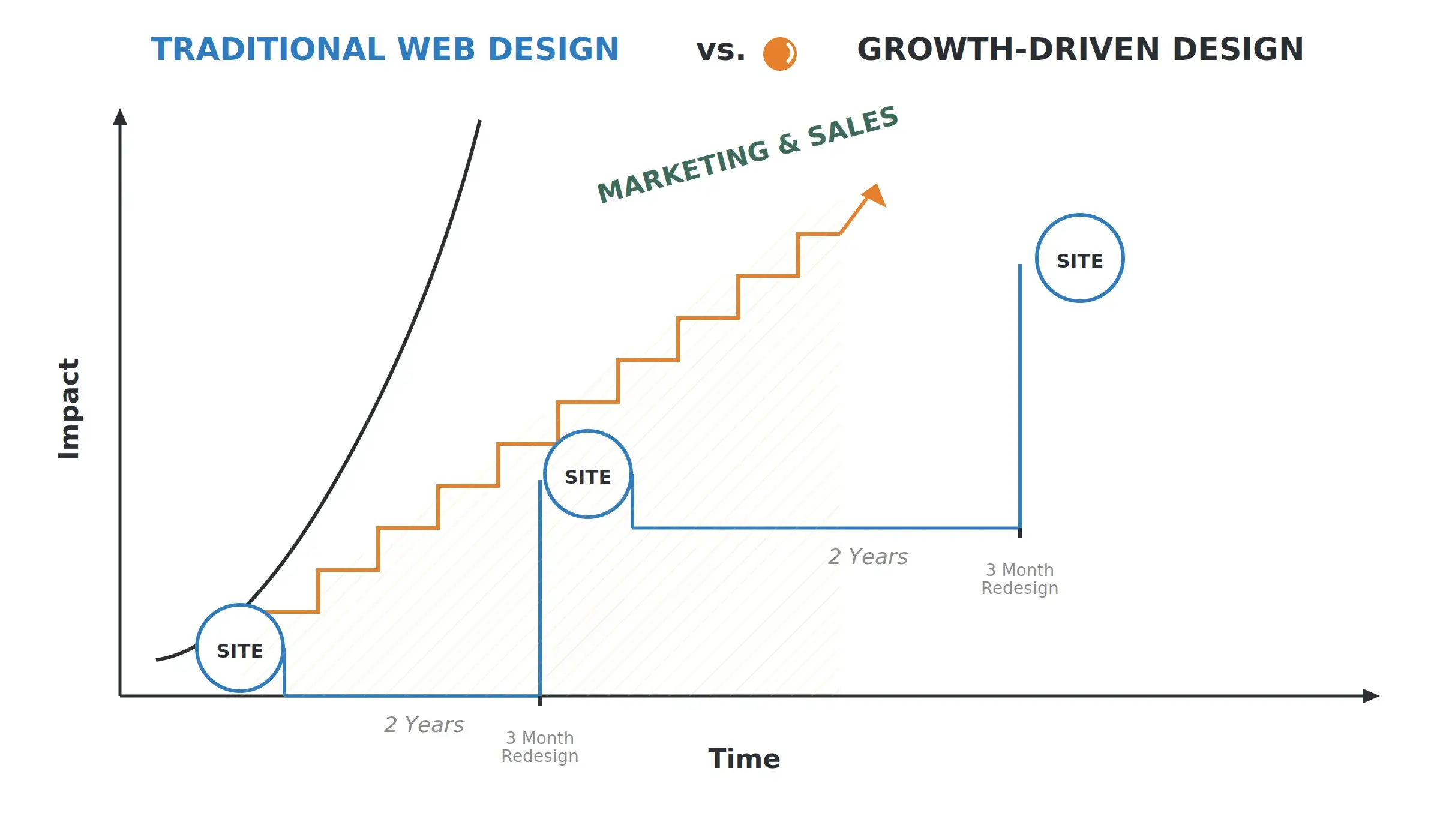
Key Benefits of Modern Experimentation
What you actually get out of modern experimentation:
- Ideas get validated faster, and you stop betting big on assumptions.
- The user experience genuinely improves, because you’re responding to what people do, not what they say in surveys.
- Conversion and engagement go up — usually in places you didn’t expect.
- Your business and your customers end up wanting the same things, more often.
There’s a bigger thing underneath all of that, though. Once a team gets used to learning from experiments, failure stops feeling like failure. A test that “didn’t work” is still data. That mindset shift is honestly the most valuable part.

Best Practices for Successful Experimentation
A few things separate the teams getting real value from the ones spinning their wheels:
- Start every test with a clear hypothesis, backed by some actual data — not a vibe.
- Focus on the stuff that moves money: CTAs, pricing, signup flows, top-of-funnel pages.
- Let experiments run long enough. Calling a test early because it “looks good” is how you ship the wrong winner.
- Build a real roadmap so you’re not just reacting to whatever leadership noticed last week.
And avoid the obvious traps: testing too many things at once (you won’t know what caused the lift), or pulling the plug on a test the moment you see green. Statistical significance exists for a reason.
The Future: Autonomous Optimization
Where this is all heading is autonomy. Systems that can spot opportunities, set up the test, and optimize on their own — without someone manually pushing every change through a queue.
That doesn’t mean people are out of the loop. It means the boring parts get automated and humans focus on strategy, on the big bets, on the experiments where judgment actually matters. The question stops being “should we test this?” and becomes “how do we keep experimentation running across every page, every channel, every customer touchpoint?”
Conclusion
The A/B testing vs AI experimentation shift isn’t really a technology trend. It’s a different way of building and running digital products.
Companies that lean into it move faster, make better calls, and end up with experiences that fit the people using them. The ones that don’t keep redesigning their site every two years and wondering why nothing sticks.
With Optimizely Web Experimentation, the path is straightforward: test continuously, learn fast, and optimize as you go.
That said, getting there takes more than a license. Royal Cyber’s Optimizely practice helps enterprises plan the program, implement the platform properly, build out experiment libraries, and graduate from one-off A/B tests to AI-driven, full-funnel optimization. Our team has delivered Optimizely engagements across retail, financial services, and SaaS — and we know what gets in the way at every stage of the maturity curve.
Want experts in your corner from day one?
Frequently Asked Question
What’s the difference between A/B testing and AI-driven experimentation?
The A/B testing vs AI experimentation question really comes down to flexibility. Plain A/B testing splits traffic evenly between two static variations and waits for a winner. AI-driven experimentation uses algorithms like multi-armed bandits to shift traffic toward winning variations in real time. It also suggests what to test based on user behavior, personalizes experiences for different segments, and reduces the traffic wasted on losing variants while a test is still running.
How long should an experiment run before I call a winner?
Long enough to hit statistical significance — usually two full business cycles, so at minimum two weeks for most sites. Cutting a test early is one of the most common mistakes. What looks like a winner on day three often flips by day fourteen once you’ve accounted for weekday vs weekend traffic, different sources, and normal day-to-day noise.
Do we need huge traffic volume to make experimentation worth it?
Not necessarily, but volume changes what you can realistically test. High-traffic sites can run quick A/B tests on small UI changes and get meaningful results in days. Lower-traffic sites should focus on bigger swings — full-page redesigns, pricing changes, or journey-level tests — where the effect size is large enough to show up faster.
How does Royal Cyber help with Optimizely implementation?
Royal Cyber is a certified Optimizely partner that handles the full lifecycle of your AI-driven experimentation platform — from setup and integration with your analytics stack to governance, experiment design, and ongoing program management. We work with companies just getting started as well as enterprise teams that want to scale from a handful of tests a quarter to hundreds, with proper measurement and reporting baked in.
Can Royal Cyber help us move from basic A/B testing to AI-driven optimization?
Yes — that’s actually one of the most common engagements we run. We assess where your program is today, build a roadmap for moving up the maturity curve, train your team on the AI and personalization features in Optimizely, and stay involved as new use cases come online. The goal is getting you to a place where experimentation runs continuously without becoming a full-time fire drill.
Talk To Our Experts
Recent Blogs
June 9, 2026
Agentforce and Microsoft Copilot Studio are the two dominant enterprise…
Read More »
June 4, 2026
Websites used to be something you built once and basically…
Read More »
June 4, 2026
Websites used to be something you built once and basically…
Read More »