Home > Blogs > Databricks > Mosaic AI Agent Framework on Databricks: The Playbook
June 9, 2026
Mosaic AI Agent Framework on Databricks: The Playbook
Table of Contents
Mosaic AI Agent Framework on Databricks has moved from analyst slideware to enterprise roadmap reality. In Royal Cyber’s Databricks practice we have shipped this kind of program across financial services, healthcare and manufacturing. This is the playbook architecture on the Databricks stack, KPIs, and the 90-day rollout we use on real engagements.
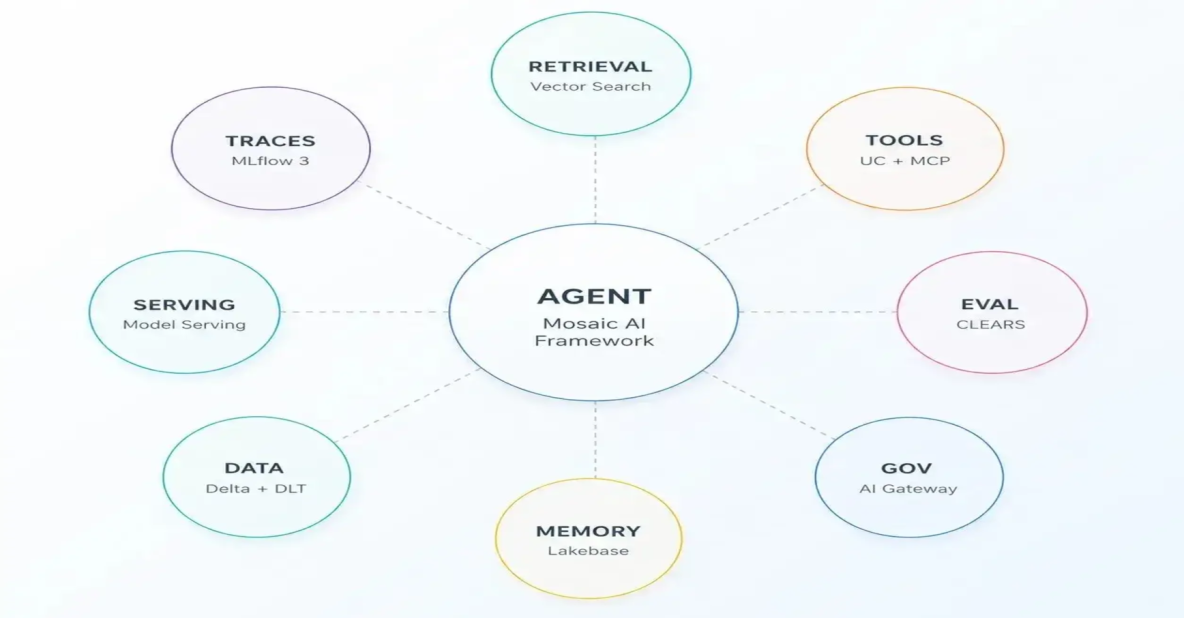
The framework went GA in early 2026 as part of a stack that finally hangs together end-to-end: Agent Bricks for task-first agent construction, MLflow 3 as the GenAI-native lifecycle and tracing backbone, managed MCP servers that expose Unity Catalog Functions, Genie, Vector Search and DBSQL as governed tools, and AI Gateway as the single control plane for every external and internal model or tool call your agent makes. LinkedIn engagement on “agent eval” posts is up 300% for a reason, the CLEARS rubric (Correctness, Latency, Execution, Adherence, Relevance, Safety) gave teams a shared vocabulary for what “production-ready” actually means.
For Databricks leaders the implication is concrete: the conversation has shifted from “should we invest” to “how fast can we ship.” The teams winning today treat Mosaic AI Agent Framework on Databricks as a capability, not a project with executive sponsorship, a product mindset and instrumented KPIs against p50/p95 model serving latency, DBU per successful task, and CLEARS pass rates.
Discover What’s New in Databricks
The Databricks Reference Architecture Royal Cyber Recommends
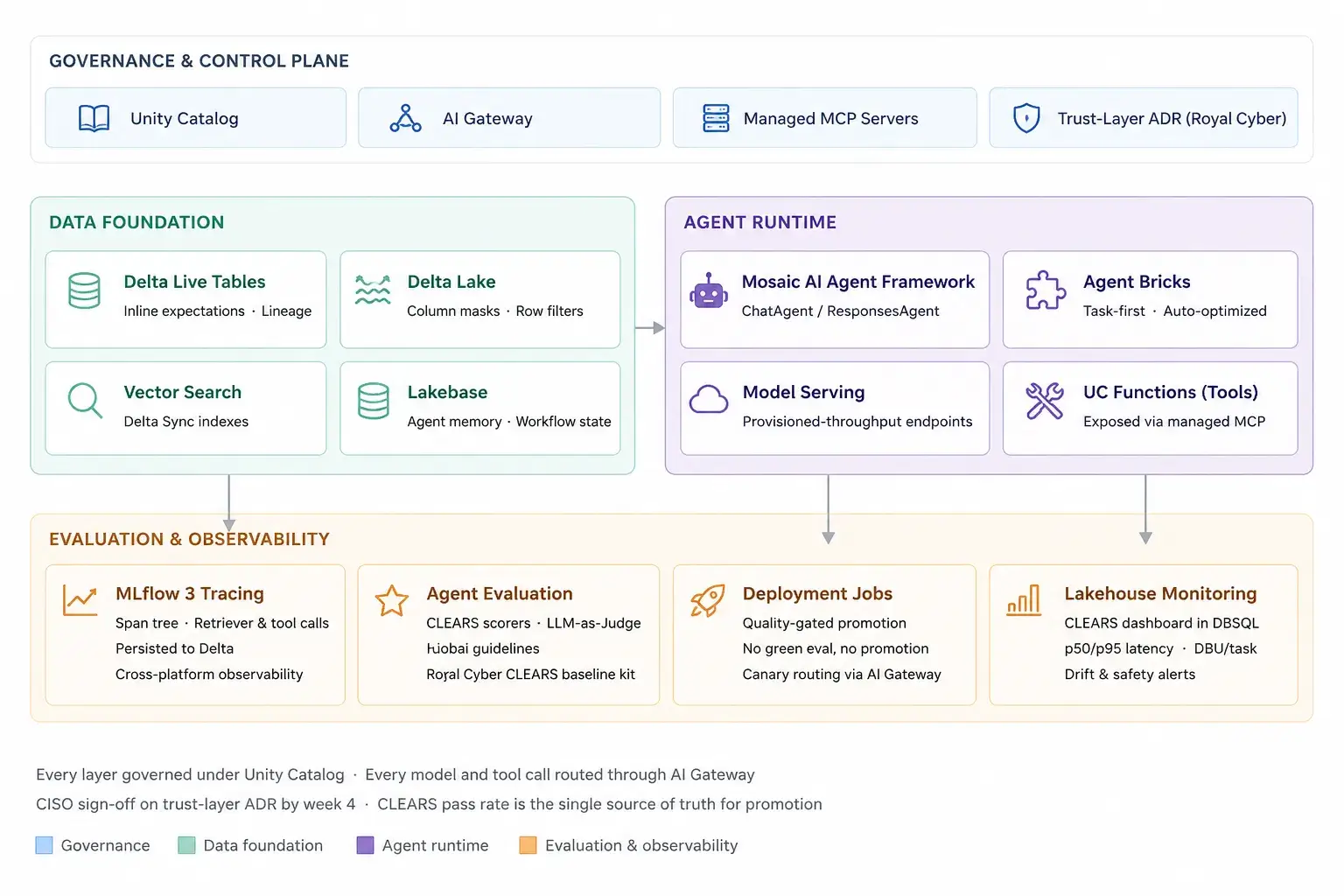
A few non-negotiables show up on every Royal Cyber engagement:
- Capability decomposition mapped to the lakehouse, not a feature backlog. Royal Cyber maps Mosaic AI Agent Framework on Databricks to two or three named capabilities your platform should expose ,typically a retrieval capability backed by Vector Search indexes, a tool-use capability backed by Unity Catalog Functions exposed via the managed MCP server, and a memory capability backed by Lakebase for persistent agent state. Tables sit in Delta with column-level masking and row filters defined in Unity Catalog. Capability thinking survives reorgs and vendor changes; feature backlogs do not.
- A modern data foundation wired through Unity Catalog. Mosaic AI only pays off when retrieval grounds in governed, observable data. Royal Cyber treats data readiness as a workstream ,Delta Live Tables (or Lakeflow Declarative Pipelines on newer deployments) for the ingestion and transformation graph, expectations declared inline so quality failures break the build instead of leaking into the agent’s context, and Vector Search indexes built as Delta Sync indexes so embeddings stay in lockstep with the source Delta tables. No drift, no nightly reconciliation job, no “why is the agent quoting last quarter’s policy” incident at a financial services client.
- A trust layer codified in an ADR – the Royal Cyber template. Guardrails, lineage, prompt and trace observability, and access controls are designed in, not bolted on. We ship a Royal Cyber Trust-Layer ADR template that codifies: which MLflow judges run on which traffic, what gets redacted before logging in AI Gateway, who can read traces in Unity Catalog, the human-in-the-loop escalation path, and the rollback trigger conditions. On healthcare engagements this template is the artifact that gets the CISO and the compliance officer to “yes” by week 4 — and it ships with PHI-aware guardrails pre-wired.
- An evaluation harness measured against CLEARS at week 4 – the Royal Cyber baseline kit. Whether you’re shipping a workflow, an agent or a data product, build the measurement before you build the feature. Royal Cyber’s CLEARS baseline kit ships with starter eval sets per sector (claims adjudication, policy Q&A, clinical summarization, manufacturing root-cause), the scorers wired in, and the CI integration ready to drop into a Databricks Asset Bundle. Concretely:
import mlflow
from mlflow.genai.scorers import Correctness, Safety, RelevanceToQuery, RetrievalGroundedness
eval_set = mlflow.genai.datasets.get_dataset("main.agents.claims_eval_v3")
results = mlflow.genai.evaluate(
data=eval_set,
predict_fn=my_agent.invoke,
scorers=[
Correctness(),
Safety(),
RelevanceToQuery(),
RetrievalGroundedness(),
],
evaluator_config={
"databricks-agent": {
"global_guidelines": {
"tone": ["Response must be professional and avoid hedging language."],
"citations": ["Every factual claim must cite a source document from retrieval context."],
}
}
},
)
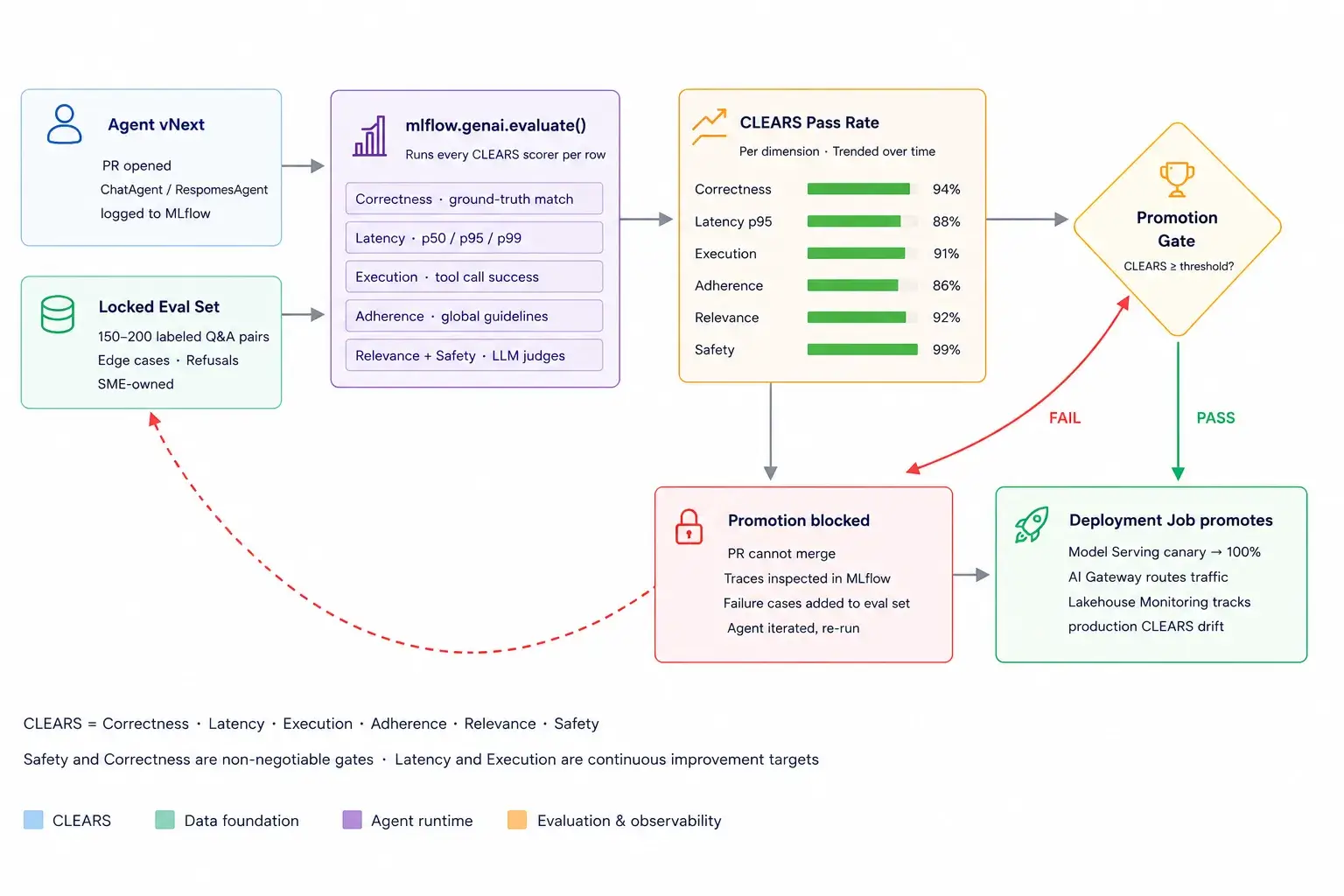
Royal Cyber baselines on a minimum of 150–200 labeled question/answer pairs covering the long tail, not just the happy path, refusal scenarios, adversarial prompts, and the gnarly edge cases SMEs flag during discovery. The pass-rate gate on the CI job is the single source of truth for “can this version of the agent be promoted.” Deployment Jobs in MLflow 3 enforce it, no green eval, no promotion.
The default Royal Cyber reference architecture:
- Governance: Unity Catalog (catalogs, schemas, volumes, functions, models, online tables)
- Data: Delta Lake + Delta Live Tables + Vector Search Delta Sync indexes
- Agent runtime: Mosaic AI Agent Framework, packaged as an MLflow
ChatAgentorResponsesAgent, deployed to Model Serving as a provisioned-throughput endpoint - Tool surface: Unity Catalog Functions exposed through the managed MCP server (UC Functions, Genie, Vector Search, DBSQL)
- Memory: Lakebase for conversation history and long-running workflow state
- Control plane: AI Gateway for routing, guardrails, rate limits, payload logging
- Observability and eval: MLflow 3 Tracing + Agent Evaluation + Lakehouse Monitoring on the trace tables
- Build velocity: Agent Bricks for task-first agents (extraction, knowledge assistant, custom text transformation) when the use case fits a standard pattern, Royal Cyber drops to the SDK only when it doesn’t
KPIs that Earn the Next Round of Funding
CIO patience for “AI strategy” is wearing thin. Royal Cyber clients getting follow-on funding pick three from this list and publish them quarterly:
- CLEARS pass rate on the locked eval set, broken out by dimension. Safety and Correctness are non-negotiable gates; Latency and Execution are continuous improvement targets.
- p50 and p95 end-to-end latency measured at the Model Serving endpoint, including retrieval and tool-call spans.
- DBU per successful task — cost-to-serve, not raw compute spend. A cheaper agent that fails more often is more expensive. This is the KPI that has earned Royal Cyber clients their phase-2 funding more often than any other.
- Deflection rate or time-to-decision for the business process the agent participates in. This is the outcome metric your CFO actually cares about.
- Time-to-production for new agent versions, measured from PR open to canary serving traffic. If it’s longer than two weeks, your Deployment Jobs and eval harness aren’t doing their job.
Avoid “users enabled” and “training completions” they’re enablement metrics, not outcome metrics. Royal Cyber has watched them die in three consecutive budget cycles at clients who didn’t switch.
Three Pitfalls we see Databricks Clients Hit
Pitfall 1 — Stack debt carried forward. Specifically: ungoverned schemas in workspace catalogs, hive-metastore residue, vector indexes that aren’t Delta Sync (so they silently drift), and UC Functions written without input validation. Agents amplify every governance gap in the data layer. Fix it before scale, or pay double later.
Pitfall 2 — Treating Mosaic AI Agent Framework on Databricks as an IT project. It touches process, change management and operating model. Run it as a cross-functional product, not an IT delivery. ML engineers and data engineers co-lead; SMEs from the target business process own the eval set; the CISO and a legal/compliance reviewer are standing members of the promotion review.
Pitfall 3 — Buying tooling before designing the operating model. Vendors are happy to sell — extra vector DBs, parallel agent frameworks, observability point solutions that duplicate MLflow Tracing. Procurement should follow architecture, not lead it. Our test: can you draw the target operating model on a whiteboard — capabilities, tool surface, eval gates, promotion path, on-call rotation — before you sign a renewal? If not, you’re not ready.
A 90-day Databricks Rollout Plan
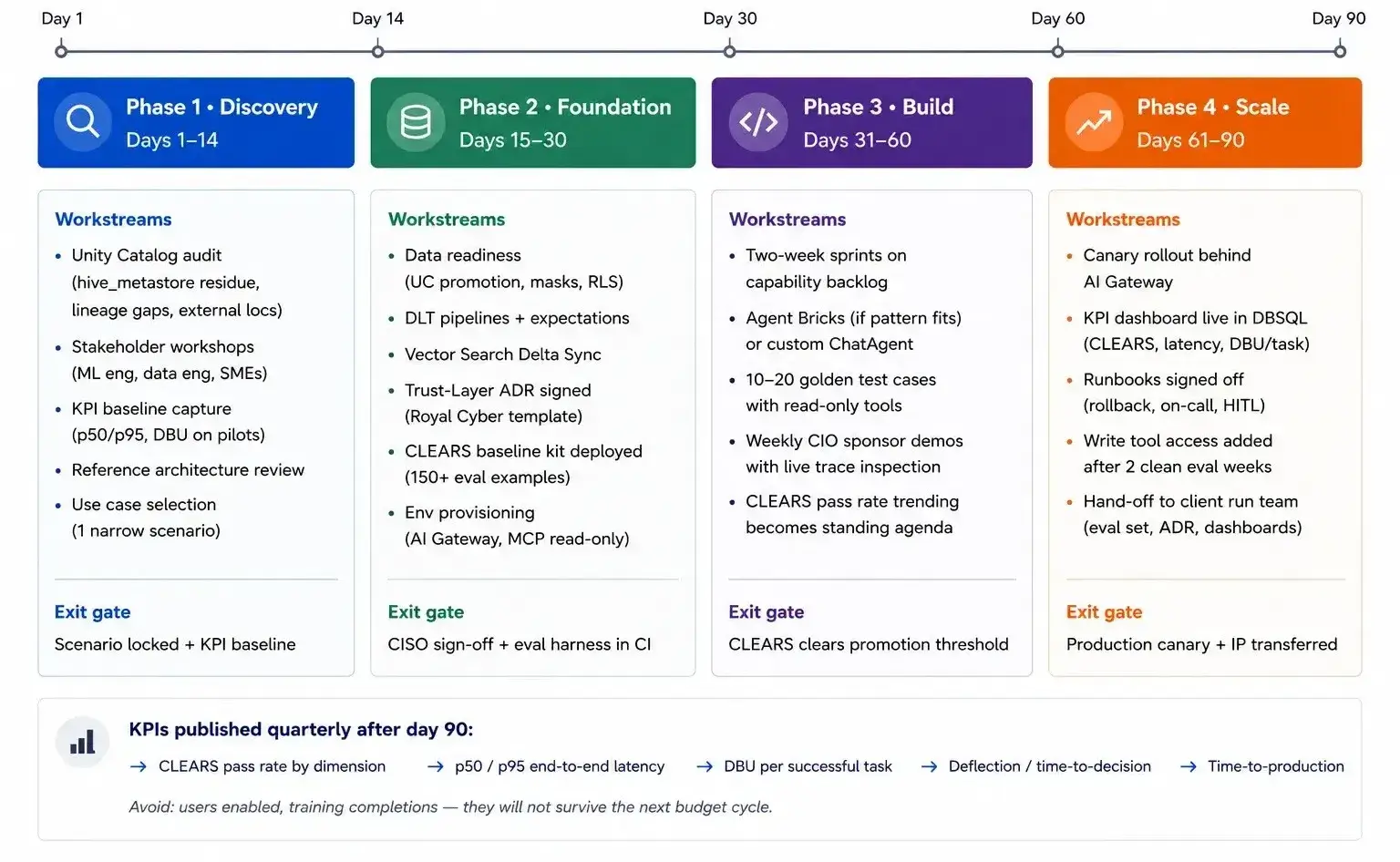
- Days 1–14 — Discovery. Current-state assessment of Unity Catalog (catalog hierarchy, external locations, lineage coverage, ungoverned hive_metastore liabilities). Stakeholder workshops with ML and data engineers. KPI baseline: capture current p50/p95 latency and DBU cost on any in-flight RAG or agent pilots. Reference architecture review against the stack above.
- Days 15–30 — Foundation. Data readiness: promote source tables to Unity Catalog, define column masks and row filters, declare DLT expectations. Trust layer ADR signed by CISO. Evaluation harness: build the v1 eval set with SMEs (target 150+ examples covering edge cases and refusal scenarios), wire
mlflow.genai.evaluateinto CI, define CLEARS thresholds for promotion. Environment provisioning: dev/staging/prod workspaces, AI Gateway configured, MCP servers connected to a read-only tool surface first. - Days 31–60 — Build. Two-week sprints against a prioritized capability backlog. Start with one narrow scenario — 10–20 golden test cases, read-only tool access, an Agent Bricks build if the pattern fits or a custom
ChatAgentif it doesn’t. Weekly demos to the CIO sponsor with live trace inspection. CLEARS pass rate starts trending at week 4 and becomes the standing agenda item. - Days 61–90 — Scale and instrument. Production rollout to a defined cohort behind AI Gateway with canary routing. KPI dashboard live in Databricks SQL on the trace tables: CLEARS by dimension, p50/p95 latency, DBU per successful task, deflection rate. Runbooks signed off — what triggers a rollback, who’s on-call, how human-in-the-loop escalations are handled. Write access for tools added only after the read-only version has clean evals for two consecutive weeks. Hand-off to the run team with the eval set, traces, dashboards and ADR as the durable artifacts.
The teams that follow the Royal Cyber playbook ship. The ones that skip the eval harness and the operating model end up with a demo that never crosses the chasm to production. We’ve seen both and this playbook is what separates them.
Conclusion
The Databricks teams that will look good in 2027 are the ones treating Mosaic AI Agent Framework as a durable capability on the lakehouse built on governed Delta data, measured with CLEARS, gated by MLflow Deployment Jobs, and operated as a cross-functional product, not the ones still pitching “AI strategy” decks on ungoverned data. The technology is no longer the hard part; Agent Bricks, MLflow 3, managed MCP servers, AI Gateway and Vector Search Delta Sync indexes are GA and integrate cleanly under Unity Catalog. The hard part is the operating model around them, who owns the eval set, who signs the trust-layer ADR, what triggers a rollback, and how DBU per successful task gets reported to the CFO every quarter. That’s where the Royal Cyber playbook earns its keep: the Trust-Layer ADR template, the CLEARS baseline kit and the 90-day rollout are repeatable IP we’ve sharpened across financial services, healthcare and manufacturing engagements, and we hand them off to your run team on day 90 so the capability stays with you. If you want a working session on your Mosaic AI roadmap or a scoped 90-day rollout against a named business outcome, reach out to the Royal Cyber Databricks team, we’ll bring the playbook, you bring the use case.
FAQ
Q1. What changed with Mosaic AI Agent Framework's 2026 GA, and why does it matter now?
The framework moved from preview to GA alongside a stack that finally hangs together end-to-end: Agent Bricks for task-first construction, MLflow 3 as the GenAI-native lifecycle layer with first-class tracing, managed MCP servers that expose Unity Catalog Functions, Genie, Vector Search and DBSQL as governed tools, and AI Gateway as the control plane for every model and tool call. The CLEARS rubric (Correctness, Latency, Execution, Adherence, Relevance, Safety) gave teams a shared vocabulary for what “production-ready” means. Before GA, most teams were stitching this together with custom code; after GA, the integration is the platform’s responsibility, not yours.
Q2. Do I need Agent Bricks, or should I build a custom agent with the SDK?
Royal Cyber’s rule: start with Agent Bricks if your use case matches a standard pattern (information extraction, knowledge assistant, custom text transformation, multi-agent supervisor). Drop to the SDK and write a custom ChatAgent or ResponsesAgent only when the pattern genuinely doesn’t fit. Agent Bricks auto-optimizes prompts and routing against your eval set, so for the patterns it covers, you’ll spend less time tuning and more time on the eval set itself — which is where the actual leverage is.
Q3. How big does the CLEARS eval set need to be before I can trust it?
Royal Cyber baselines at 150–200 labeled examples for a v1 production gate. Fewer than that and you’re optimizing for the happy path; more isn’t useful until you’ve watched what fails. The composition matters more than the size: roughly 60% representative real questions, 20% edge cases the SME flags, 10% refusal scenarios (questions the agent should decline), and 10% adversarial prompts. Failure cases from production traces feed back into the eval set every sprint that’s how it stays honest.
Q4. How do we measure DBU per successful task, and why is it the KPI that earns follow-on funding?
Tag each request at AI Gateway, join trace records to Model Serving usage records in DBSQL, and divide DBU consumption by the count of requests that passed your CLEARS threshold. Raw compute spend is misleading – a cheaper agent that fails 30% of the time is more expensive than a pricier one that fails 5%. CFOs respond to cost-per-successful-outcome in a way they don’t respond to “we spent X on DBUs this quarter,” and it’s the KPI that has earned Royal Cyber clients their phase-2 funding more often than any other.
Q5. What if our Unity Catalog isn't ready — do we have to wait?
No. Royal Cyber treats data readiness as a parallel workstream, not a prerequisite. Phase 1 of the 90-day plan includes a targeted UC audit and promotion of only the schemas the first use case actually needs. Trying to govern the entire estate before shipping anything is how programs stall for 18 months. Govern what the first agent touches, ship it, then expand and let the trust-layer ADR (signed by CISO at week 4) codify the policies that scale to the next use case.
Author
Pooja Reddy Sodum
Marketing Executive
Talk To Our Experts
Recent Blogs
June 9, 2026
Agentforce and Microsoft Copilot Studio are the two dominant enterprise…
Read More »
June 4, 2026
Websites used to be something you built once and basically…
Read More »
June 4, 2026
Websites used to be something you built once and basically…
Read More »