
Extract, Transform, and Load with Azure Data Factory

Written by Hafsa Mustafa
Technical Content Writer
November 2, 2022
Azure Data Factory is a cloud-based serverless platform for ETL and data integration. It orchestrates data pipelines and automates their running for data migration. It is fully managed and enables you to create workflows without writing any code. This blog will expound on how you can do ETL on Azure Data Factory. But first, let’s see what ETL means.
What is ETL?
ETL stands for Extract, Transform, and Load. It refers to the whole process of collecting data from diverse sources like Azure Blob Storage, on-premises SQL database, and an azure SQL data warehouse, transforming it, and finally loading it into a target system.
ETL is used to extract data from sources like databases, data warehouses, CRM systems, the cloud, etc. The most common purpose is to ingest structured and unstructured data into a centralized repository. The ultimate goal is to give historical context to the present and future data, enable analysts to generate data-driven insights and make informed policies.
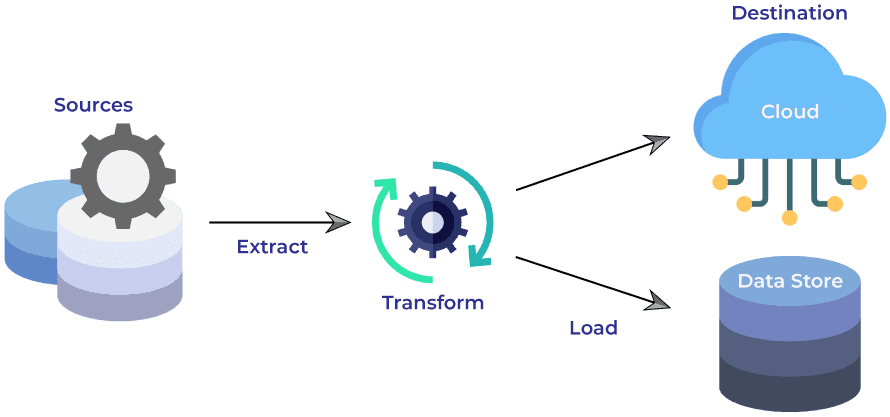
ADF Components in Action
Before we proceed to the process of creating a data pipeline with Azure Data Factory, let’s look at the basic idea and components related to the ETL process.
Pipeline
A pipeline in Azure Data Factory refers to a series of activities that get different jobs done to make a workflow. You can basically control the data flows through two features:
- Triggers; can be used to schedule a pipeline for a specific time and date without any interventions.
- Parameters & Variables; parameters tend to remain constant during the runs, whereas variables can be changed during the runs.
Linked Services
Linked Services tell us about the connections to the data sources and the runtimes required for the processing. The configuration parameters for specific data sources are stored in linked services. They are required for developing connections with external sources. You can create ADF by switching to the “Manage” tab in the Azure Data Factory.
Datasets
Datasets can be defined as representations of data that are used within a pipeline. They can be in a file or table format. You need to structure your data correctly to keep your workflow efficient. For this purpose, you can rename and reorganize your folders to give them more meaning.
Copy Activity
The copy activity in Azure Data Factory lets you copy your data from a source and transfer it to a sink. It also supports basic mapping for an organization, like typecasting and renaming. Once you copy the data, you can transform it further as you like.
Triggers
Triggers allow you to schedule your pipelines for a specific time and date. To create a trigger, you can click on the “Trigger” tab in your pipeline. You can also activate your trigger to set it in motion right away or let it stay inactive and click on it later by going into your “Manage” tab.
Summarizing the Steps
Here are the steps that you need to follow to perform basic ETL processing on Azure Data Factory.
Step 1
You need to log in to your Azure Data Portal to access Azure Data Factory. Now, click on the “create pipeline” option to set the ball rolling. You can also create a new pipeline through Factory Resources, given under the “pencil” icon.
Step 2
You need to name your pipeline and write the most suitable description for it that describes its purpose.
Step 3
Now, select the activities for your pipeline from the range of options given below the Activities section. For instance, if you are aiming to copy data from one source to another, you can select the “copy activity,” which will load data into the destination. Each copy activity has a source and a sink. Also, you can use the “Parameters & Variable” tab to set input parameters for the data transformation step.
Step 4
A dataset needs to be chosen for the source. You can select your sources and targets from a variety of dataset options like a data lake, SAP, Azure database, Blob Storage file, spark, etc. Remember, if you need to transform your data into a uniform format, you should select “data transformation” as your activity first and park the data till it finishes.
Step 5
From the “Copy Source Data,” you need to move to the “Data Flow” activity and click on the + New option in its settings to open a new tab for data transformation purposes.
Step 6
You can use options like “Sink” and “Mapping” to produce your transformed file and also to configure the columns and align your data.
Step 7
Now, you can use the “copy activity” to move the transformed data to your destination.
Conclusion
Are you looking for ways to integrate your data assets? Royal Cyber data experts have years of experience in enabling businesses to embrace modernization to get the bigger picture while producing analytics and strategies. You can contact our experts to discuss your business goals and challenges.
Azure Data Factory orchestrates moving data within systems, be they based on cloud or on-premises traditional hardware. It facilitates organizations in integrating their data to construct a single source of truth for different departments.
Recent Blogs
 Websites used to be something you built once and basically forgot about. That doesn’t work …Read More »
Websites used to be something you built once and basically forgot about. That doesn’t work …Read More »- Learn how to plan an Optimizely CMS 13 upgrade with .NET 10, Optimizely Graph, Visual …Read More »
- Learn how AI meeting notes automate summaries, action items, and insights from video meetings using …Read More »


