
Home > Blogs > Databricks > Getting Started with Databricks LakeFlow
February 23, 2026
Getting Started with Databricks LakeFlow
Table of Contents
A core challenge in modern data engineering is tool fragmentation. Data teams are often forced to manage a disconnected set of specialized tools for orchestration, transformation, and ingestion. This disjointed approach introduces significant operational complexity, creates governance blind spots, and leads to persistent maintenance overhead that ultimately hinders reliable data reporting.
Databricks LakeFlow directly addresses these challenges. As a unified end-to-end platform, it lets you build pipelines from various sources in batch or stream mode using built-in connectors. You can then observe and test transformations within its canvas UI. Royal Cyber, a Databricks-certified solutions partner, helps enterprises implement LakeFlow to consolidate their stack, reduce technical debt, and streamline governance through native Unity Catalog integration.
Explore our comprehensive Databricks consulting services, designed to de-risk and accelerate your LakeFlow adoption.
Leverage certified expertise for your migration
LakeFlow eliminates the use of custom connectors or third-party integration tools – activities that often eat developer time as teams scramble to keep abreast of frequent API updates in applications like ServiceNow, Salesforce, and Workday. Through LakeFlow Connect, those integrations can be fully process managed as default, and enabled engineering staff may focus on the outcome of analytics.
In addition to ingestion, the declarative pipeline structure at LakeFlow automates many complexities. The processes of change-data capture (CDC), incremental processing, error recovery, and dependency management are all automated. The platform identifies the most optimal course of execution by stating the desired state of data. This imperative to declarative thinking minimizes the code volume, bugs and thus speeds up the delivery of new data products.
Components of LakeFlow
Lakeflow consists of three tightly integrated components working together.
Lakeflow Connect
Lakeflow connect serves as the entrypoint for getting all of your data into datarbicks, you just have to point and click on the connector of your choice through which you can get your material from databases like SQL server, MYSQL, PostgresSQL and Oracle plus enterprise apps like salesforce, Workday, ServiceNow and share point.
A key feature is built-in Change Data Capture (CDC), which leverages native change tracking in source systems. After the initial load, you only pull what has changed, eliminating costly nightly full-table scans.
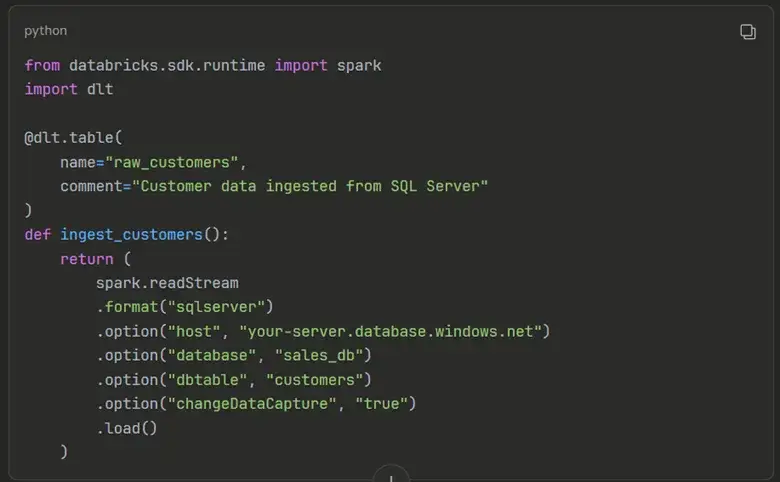
LakeFlow Pipelines (Spark Declarative Pipelines)
This native transformation tool, built on Delta Live Tables, uses a declarative approach. You define what your tables should contain, not how to build them. The framework allows you to embed data quality expectations (
EXPECT constraints) directly into pipeline definitions. You can decide to drop, quarantine, or fail records that violate rules—no separate validation scripts are needed. 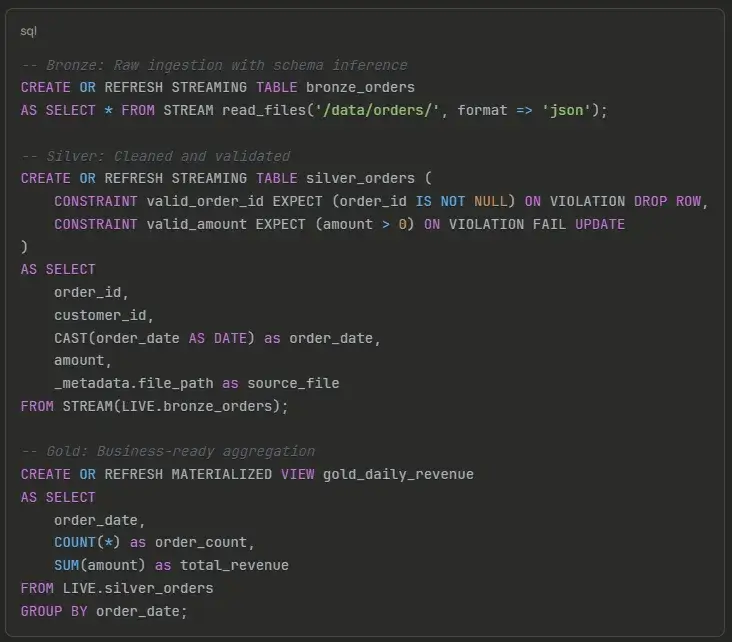
LakeFlow Jobs
This is the orchestration layer that ties everything together. It handles scheduling, dependency management, alerting, and CI/CD integration. It provides full observability into run history, data freshness, SLA breaches, and resource utilization from a single pane of glass.
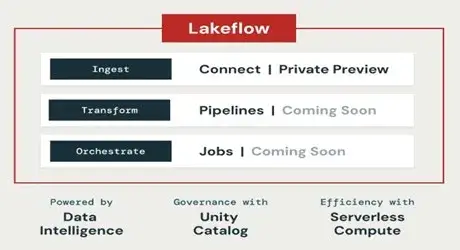
Figure 1: LakeFlow unifies Connect, Declarative Pipelines, and Jobs under the Data Intelligence Platform with Unity Catalog governance.
Why Lakeflow Actually Makes Sense for Your Business
The Tool Sprawl Problem
- The majority of data teams use different orchestration (Airflow), ingestion (Fivetran or custom scripts), and transformation (dbt or Spark) tools.
- It results in endless context switching, unequal monitoring dashboards, and a lot of work just to ensure systems are connected with each other.
- This sprawl is concentrated in LakeFlow.
- There is no more inter-interface switching between teams and can solve problems on one platform.
- This kind of consolidation typically saves 40 -60 percent in the time spent in developing pipelines and enables engineers to code business logic rather than write glue code.
- In the case of governance teams, there are no stitching and piecing of audit trails across several sources and data lineage becomes easy.
Built-in Governance
- The registration of a table in Unity Catalog occurs when LakeFlow materializes it.
- The controls of access, classifications of data and the lineage are active on the first day of operation – governance is not an add-on.
- This is important in controlled industries where the need to prove data provenance and access is a prerequisite.
- The intrinsic data-quality requirements give a systematic option to ad-hoc validation scripts which are often neglected.
The Economics of Serverless
- LakeFlow is built on serverless computing.
- Pipelines increase in size as per workload requirements and reduce during idle time.
- This model is used by teams facing volatile amounts of data (e.g. processing month-ends or seasonal peaks) so that they can charge actual usage as opposed to pre-provisioning against worst-case scenarios.
- It also eliminates the need to plan infrastructure capacity of platform teams.
Figure 1: LakeFlow unifies Connect, Declarative Pipelines, and Jobs under the Data Intelligence Platform with Unity Catalog governance.
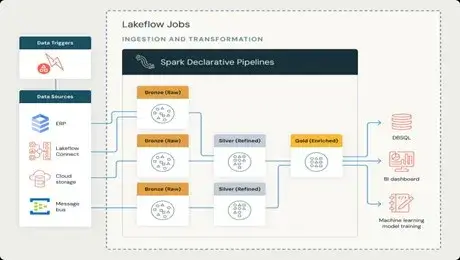
How Lakeflow Structures Your Data
LakeFlow is built with the medallion architecture, which is the default scheme of arranging data in a lakehouse. In this design, data moves in three logical layers, which is perfected at each level.
Bronze: The Raw Landing Zone
The Bronze layer is the first destination of all the source data in their natural, pure condition. This ingestion is automated with LakeFlow Connect which maintains the original data format and includes vital metadata such as provenance and arrival time. It is important to preserve this raw layer to enable reprocessing and auditing of records to have a full lineage record to to the source system.
Silver: The Trusted Single Source of Data Cleaning
Raw data is converted to trusted datasets to be utilized in queries in the Silver layer. This includes the process of deduplication, standardization of format and the implementation of the rules of data quality. Here the records are quarantined and do not propagate downstream with corrupted data. Silver layer provides base layer of clean, conformed single source of truth of core business entities.
Gold: The Business-Optimized Layer
The Gold layer holds data that has been formatted to be consumed in particular analysis and operation. Tables are performance-focused and user-friendly, either as aggregated measures as part of dashboards, denormalized feature stores as part of machine learning, or curated views as part of business departments. One Silver data may be used to generate several Gold tables that can be used by different audiences. LakeFlow also supports batch and streaming updates of this layer, which enables teams to trade off between the latency needs and the cost.
Migration of Existing ETL with LakeFlow and LakeBridge.
The majority of organizations when looking at LakeFlow are not commencing new projects; instead, they have already implemented ETL workloads on a platform such as Informatica, Talend, SSIS, or an old SQL either on Teradata or Oracle. The major obstacle to modernization is the possibility of having to manually rewrite these pipelines. Here, LakeBridge, a tool that speeds up the migration of Databricks, is necessary.
LakeBridge: The Migration Accelerator.
The LakeBridge process operates in two major steps to de-risk the transition:
Complete Analysis: LakeBridge initially examines your current SQL and ETL code, locating complexities, proprietary functions and platform-specific logic. This automated testing gives a correct scope of work which removes uncertainty and teams do not underestimate the work needed.
Automated Code Conversion: LakeBridge will convert the legacy code into native Databricks code, after the assessment. It performs the conversion of proprietary functions, structural clauses and stored procedures automating an estimated 80% of the migration workload. This changes it into a rewrite rather than a complete rewrite and a review and refinement of converted code.
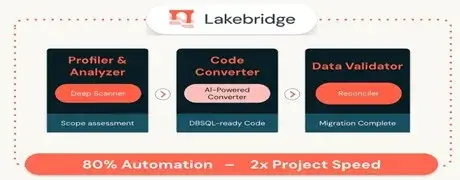
Figure 4: LakeBridge provides assessment, conversion, and validation capabilities that automate up to 80% of migration effort.
Join our exclusive webinar, “Automating ETL Migration to Databricks with Lakebridge,” for a live deep-dive into the assessment and conversion process.
See LakeFlow and Lakebridge in action.
LakeFlow: Making the Migrated Code Operational.
Such a hybrid changes the migration discourse. Rather than a comprehensive rewrite of the manual, the path uses LakeBridge to automatically do all the heavy lifting and LakeFlow to do the simple operations. It changes the engineering position to validator as well as enabling the teams to modernize their stack without compromising on existing logic or paying prohibitive costs.
Key Considerations Before You Start
- Start with a Pilot: Choose one well-understood, contained pipeline. Migrate it end-to-end to learn the process before scaling.
- Treat Pipelines as Code: Use Databricks Asset Bundles (YAML) to version pipelines in Git and integrate them into your CI/CD workflows.
- Avoid Lock-In: The Spark Declarative Pipelines framework is open-source. The skills and code your team develops are built on portable foundations.
Partnering with Royal Cyber
Royal Cyber’s Databricks practice brings deep expertise in enterprise data engineering, with certified architects and engineers who have delivered LakeFlow implementations across financial services, healthcare, retail, and manufacturing sectors. Our team can help your organization:
- Assess your current data infrastructure to identify high-value migration candidates and estimate effort for LakeFlow adoption
- Design medallion architecture tailored to your data domains, governance requirements, and analytical use cases
- Execute migrations using LakeBridge to accelerate the transition from Teradata, Oracle, Snowflake, or SQL Server while minimizing risk
- Implement CI/CD pipelines using Databricks Asset Bundles with GitHub Actions or Azure DevOps for enterprise-grade deployment automation
- Provide ongoing managed services including pipeline monitoring, performance optimization, and platform upgrades
References
- Databricks Blog: Announcing the General Availability of Databricks LakeFlow — databricks.com/blog/announcing-general-availability-databricks-lakeflow
- Databricks Product: LakeFlow Jobs — databricks.com/product/data-engineering/lakeflow-jobs
- Databricks Blog: Introducing LakeBridge — databricks.com/blog/introducing-lakebridge
- GitHub: LakeBridge Open Source Project — github.com/databrickslabs/lakebridge
Figure Sources
- Figures 1, 2, 4:databricks.com/blog/announcing-general-availability-databricks-lakeflow
- Figure 3: databricks.com/product/data-engineering/lakeflow-jobs
Attend our webinar to understand the tools, then connect with our certified Databricks team to discuss your specific migration landscape and build a tailored plan.
Get a personalized assessment for your legacy ETL.
Frequently Asked Questions (FAQs)
Q. How does LakeFlow simplify data governance compared to a multi-tool setup?
Unity Catalog is a native part of LakeFlow. All generated tables are automatically registered, which means that they are centralized access controlled, data classified, and with lineage. This avoids the manual synchronization of governance policies between different ingestion, transformation and orchestration tools, developing one enforceable governance layer.
Q.What specific advantages does Royal Cyber bring as a Databricks-certified partner?
Our qualified architects and engineers have profound and proven experience in the Databricks platform. This equates to established methods of implementation, best-practice architecture, and access to special resources, so your LakeFlow implementation is performance-optimal, cost-optimal and governance-optimal at the outset.
Q. I have extensive legacy ETL code. Is migrating to LakeFlow practical?
Yes, with the joint of LakeBridge and LakeFlow. LakeBridge will automate the evaluation and transformation of legacy SQL/ETL code (estimates of 80 percent automation), eliminating a large amount of manual labor. The modern platform is then offered by LakeFlow to carry out, coordinate and control the migrated pipelines, such that the transition becomes efficient and risk-free.
Q. What will the upcoming webinar on Databricks ETL Migration & LakeBridge cover?
The webinar will take a step-by-step tour of the automated migration process of the old systems into the LakeFlow systems. We will show the capability of assessment and conversion of LakeBridge, operationalise pipelines by converting into LakeFlow, as well as will share real-life examples of how to shorten migration timelines and decrease risks. Register here to secure your spot.
Q. Can Royal Cyber help us build a business case and roadmap for adopting LakeFlow?
Absolutely. We usually begin by conducting an assessment workshop during which we examine your existing tool spreads, calculate the operational overhead and technical debt, and find high value pilot pipelines. Then we offer an in-depth ROI analysis, a staged implementation plan, and an understanding of the efficiency and governance benefits you are likely to receive.
Talk To Our Experts
Recent Blogs
June 9, 2026
Agentforce and Microsoft Copilot Studio are the two dominant enterprise…
Read More »
June 4, 2026
Websites used to be something you built once and basically…
Read More »
June 4, 2026
Websites used to be something you built once and basically…
Read More »