From Minutes to Milliseconds with Elasticsearch
It is difficult to search when we have a huge data quickly (e.g. 10 TB or more) and takes time. Thanks to Elasticsearch which has made life easy and helped solve this issue.
Here we will discuss the problem we faced searching large data (10 TB) and how we have solved it with Elasticsearch.
Use Cases
- Should support contains search, start-with search and exact search.
- Should support sort.
- Retention rate of 7 days.
Design One
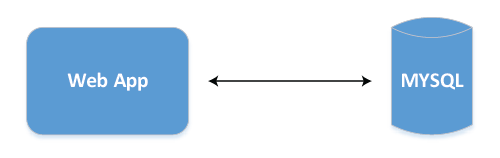
We started with my-sql as our database. Most of the queries needed to do a full table scan. Some of our searches took 2 minutes to complete. Then we indexed few columns that reduced starts-with and ends with searches.

However, contains searches still took 2 minutes. It cannot use b-tree data-structure instead it has to do a full table scan.

Design Two
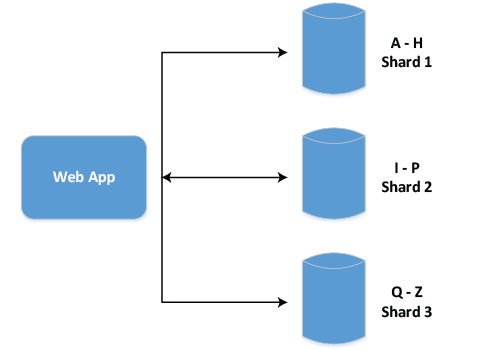
Since we were using company_category in most of our queries, we sharded our data with company_category. Still, some queries were slow (queries that did not have company_category) but it’s a significant improvement from our previous design. The average time was 1 sec. We changed the search logic as below.

This solved most of our problem but still some queries needed search across shards. Aggregating result also became more complex for those queries.
Design Three
In the next design, we tried a NoSQL data store, a distributed search engine Elasticsearch.
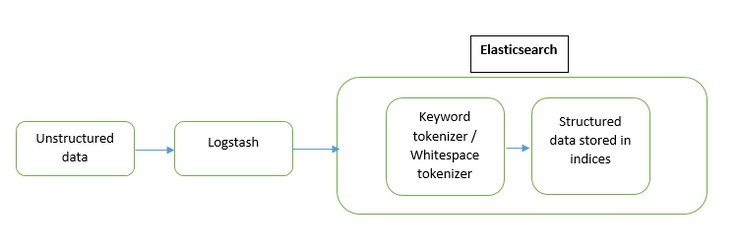
Elasticsearch produces search results faster than the SQL databases by using inverted index concept (Creating a list of tokens with all its associated documents when indexing).
Before storing the documents in the indices, the mapping for the fields of the documents is essential for search.

We stored the company name of each document as two different formats (as text (analyzed) and keyword (non-analyzed))
For starts-with search with the query as below, the wildcard search on company_name.keyword field (if performed on the text field then right set of results will not be returned) and it produced the search results in just around 1 sec.

For contains search with query as below, the query_string search on text field of company_name which fetched the result in around 1 sec as retrieving the tokens from inverted index is more efficient in Elasticsearch.
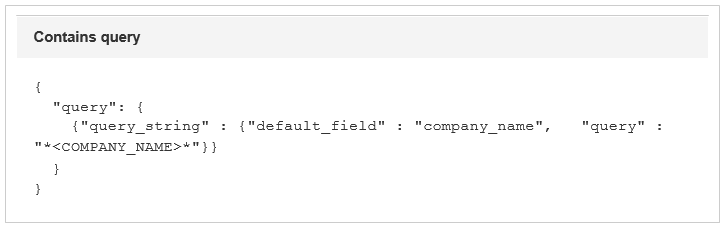
For exact search with query as below, the match query on company_name field fetched the result in around 1 sec irrespective of the size of the data in database.

For the above searches, sorting can be performed on the resultset by appending the below query,

Also to maintain the retention rate, the data can be stored as timeseries indices (*YYYY-MM-DD) and by executing action files of curator plugin having a configuration to delete the indices that are older than n days.
Hence, when it comes to sorting and searching on a huge set of data, Elasticsearch would be the right solution. It offers to search in various perspectives with faster querying if an appropriate mapping is provided at index time. Also maintaining retention rate is simplified by the use of elasti csearch-curator plugin.
Royal Cyber
Royal Cyber has extensive experience using Elasticsearch and can help you quickly search irrespective of the data size. For more information, click here.
by Francis Salvin