Scalable and Reliable Apache Kafka with IBM Event Streams
Day to day, you see constant and continuous streams of data consequences. Most businesses face problems of having too much continuous data flow, and collecting all of this data is not easy as it is pooled from various sources in different formats.
One way to solve this problem is to use a messaging system. Messaging systems offer seamless integration between distributed applications with the help of messages. Apache Kafka can provide solutions for messaging, as well as a lot of other use cases.
Apache Kafka formulates a reliable messaging core of IBM Event Streams. IBM Event Streams builds upon IBM Cloud Private Platform to deploy Apache Kafka in a robust way. It embraces a UI design aimed towards application developers just getting started with Apache Kafka, as well as users operating a production cluster.
IBM Event Streams Features
Apache Kafka deployment maximizes the spread of Kafka brokers across the nodes of IBM Cloud Private Cluster.
Health check information and opportunities to solve issues with the brokers and clusters.
Security with authorization and authentication using IBM Cloud Private.
Geo-replication of topics between clusters to support high availability and scalability.
UI for browsing messages to view and filter thousands of messages.
Encrypted communication between internal components and encrypted storage by using IBM Cloud Private.
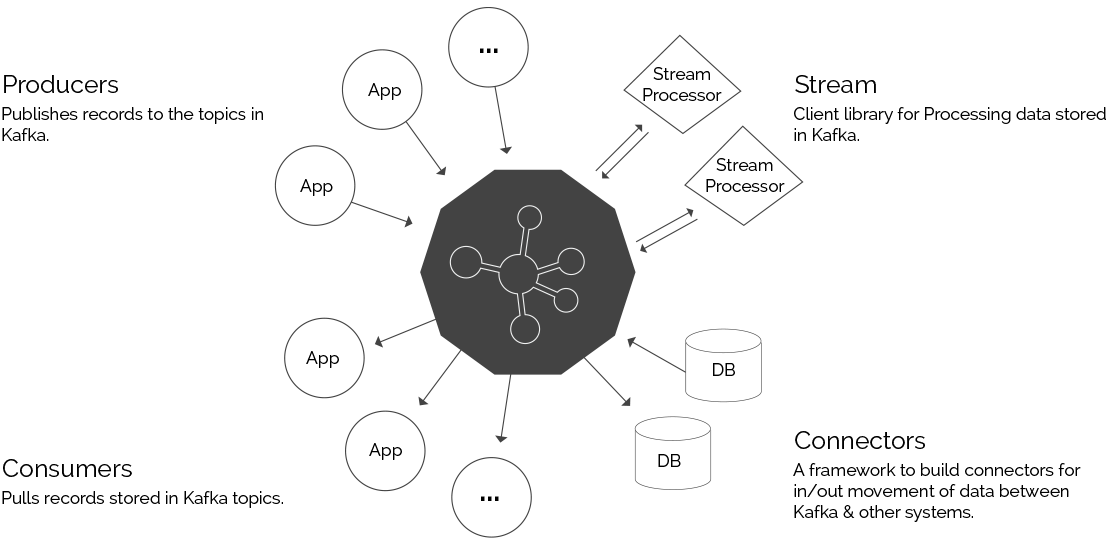
Kafka Key Concepts
Producer
Consumer
Broker
Cluster
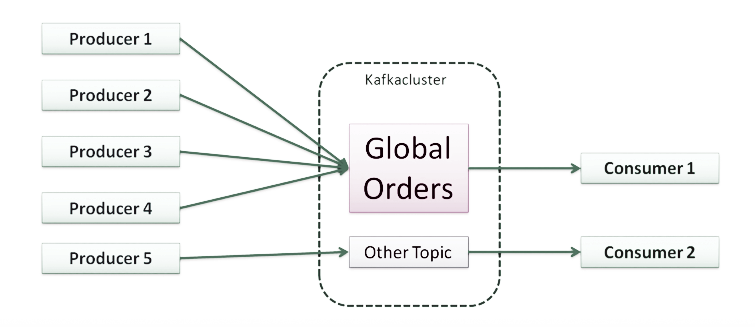
Topic
Partition
Message
Consumer group
| ID | Value | Description |
|---|---|---|
| 1 | Producer | An application that sends data to Kafka |
| 2 | Consumer | An application that receives data from Kafka |
| 3 | Broker | Kafka Server |
| 4 | Cluster | Group of computers |
| 5 | Topic | A name of a kafka stream |
| 6 | Partition | Part of a topic |
| 7 | Offset | Unique id for a message within a partition |
| 8 | Consumer groups | A group of consumers acting as a single logical unit. |
Producer - A method that publishes streams of messages to Kafka topics. A producer can distribute to one or more topics and can choose the partition that stores the data.
Consumer - A practice that uses messages from Kafka topics and processes the feed of messages.
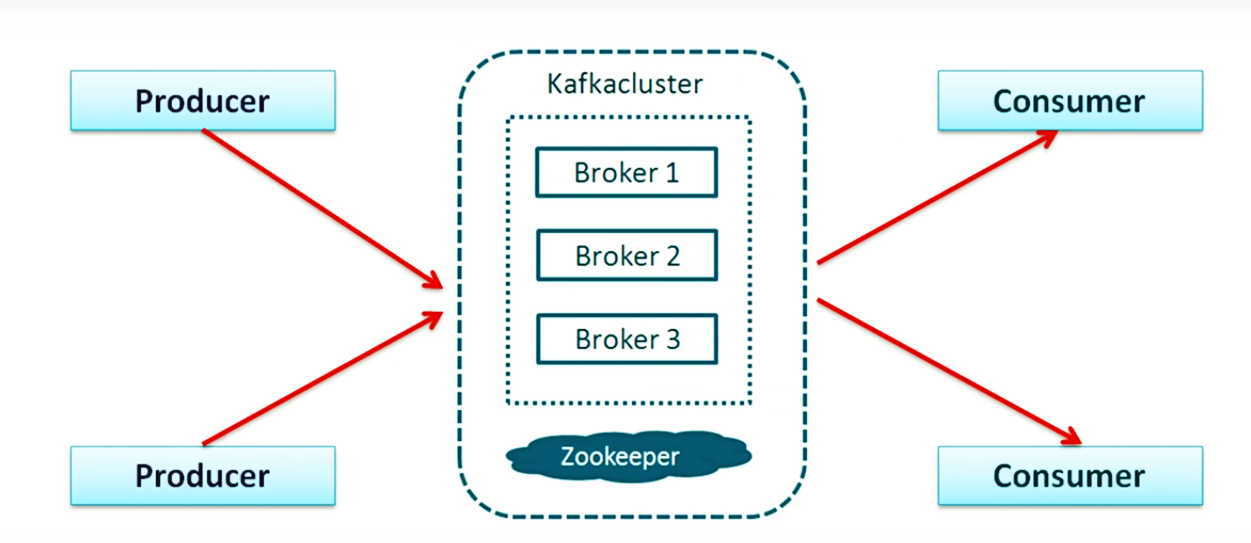
Cluster - Kafka runs as a cluster of one or more servers. It is balanced across the cluster by distributing it among the servers.
Topic - A stream of messages is stored in groups titled topics.
Partition - Each topic consists of one or more partitions. Each partition has an ordered list of messages. The messages on a partition are provided with a monotonically increasing number called the offset.
Offset - Sequence Id given to messages as they come in the partition.
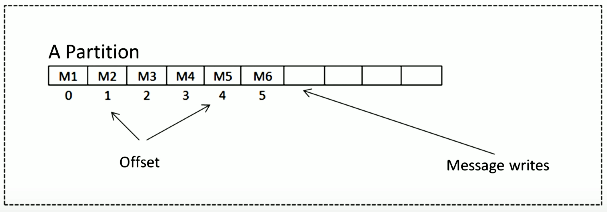
To locate the message, we should know these three things: Topic Name, Partition Number, and Offset.
Message
The unit of data in Kafka. Each message is denoted as a record that has two parts: key and value. The key is used for data about the message, and the value is the body of the message.
Consumer group
A group of one or more consumers together use the messages from a set of topics. Each consumer in the group can read the messages from the partition that it is assigned to.
Kafka is scalable and allows the creation of multiple types of clusters.
Single Node Single Broker Cluster
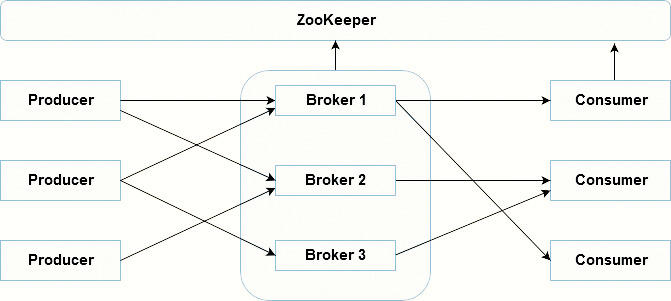
Single Node Multiple Broker Cluster
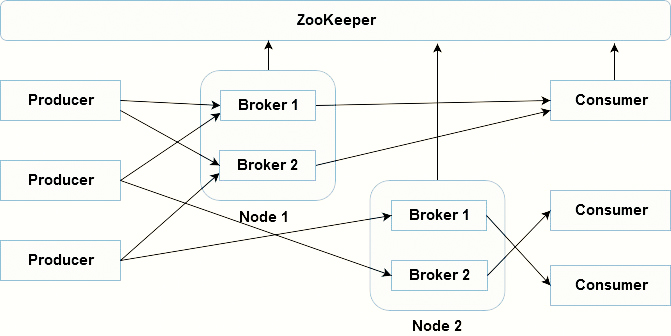
Multiple Nodes Multiple Broker Cluster
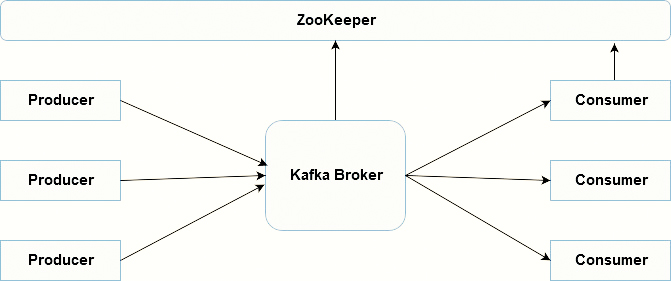
What’s the role of ZooKeeper?
Each Kafka broker synchronizes with other Kafka brokers using ZooKeeper. Producers and Consumers are alerted by the ZooKeeper service about the existence of new brokers or error of the broker in the Kafka system.
Use Cases
Here is a depiction of a few of the prevalent use cases for Apache Kafka.
Messaging - Kafka works well as an alternative for a traditional message broker.
Stream Processing - Many users use Kafka process data in handling pipelines that consist of multiple stages, where raw data is consumed from Kafka topics are then transformed into new topics for further use.
Website Activity Tracking - The original use case for Kafka was to rebuild a user activity tracking to publish-subscribe feeds.
Metrics - Kafka is used for monitoring data. This includes aggregating statistics from distributed applications to produce consolidated feeds of operational data.
Log Aggregation - Many people use Kafka as a replacement for a log aggregation solution.
Event Sourcing - Event sourcing is a style of application design where changes are logged as a time-ordered sequence of records.
Commit Log - Kafka can serve as an external commit-log for a distributed system.
Royal Cyber can you be your technology partner for such event streaming solutions. For more information, email us at [email protected] or visit www.royalcyber.com.

